N-Tree
This tutorial features a simple hydrodynamics code based on Smoothed Particle Hydrodynamics (SPH) applied to a classic hydrodynamics problem called the Sod shock tube. Through this example, it presents the different capabilities and interface of the N-Tree topology.
SPH sodtube
SPH is a meshfree method that uses particles to represent units of mass in space.
Each particle interacts with neighboring particles using a smoothing length (h) and a function called a kernel (W), the following figure illustrates this concept of area of influence.
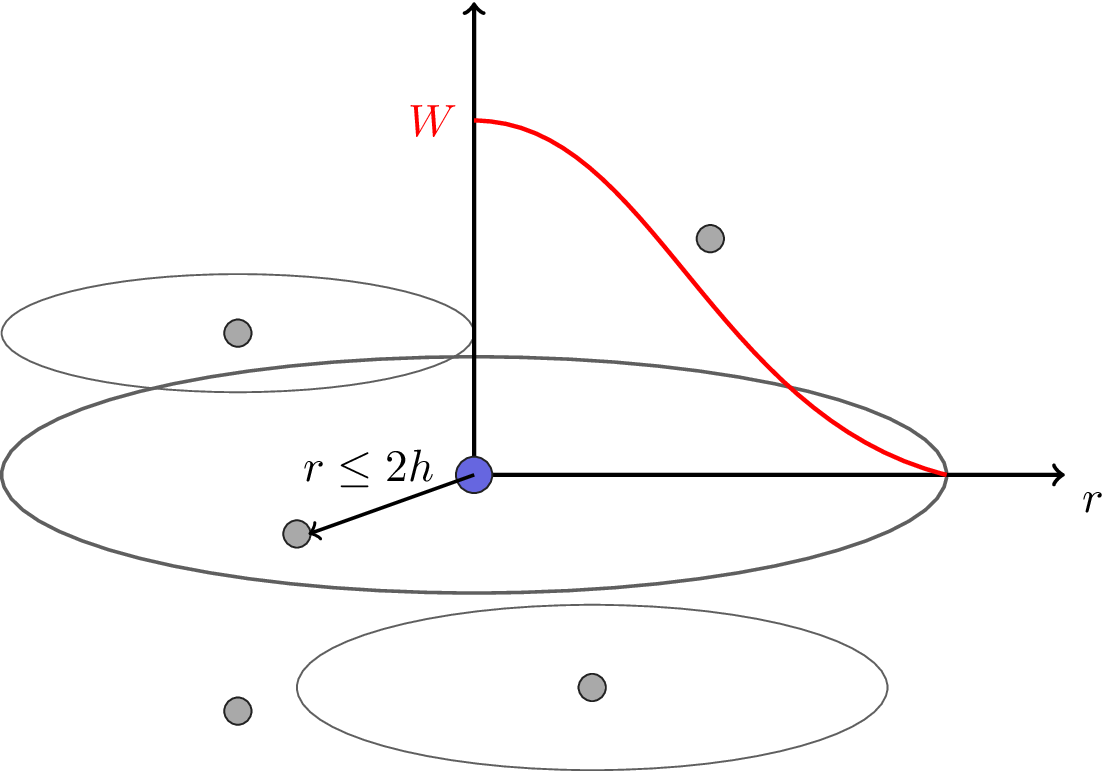
Fig. 9 Smoothed Particle Hydrodynamics particle interaction.
In order to represent this system of particles and to efficiently find neighboring particles, the best implementations are based on a tree data structure. Each particle is assigned a unique key using space-filling curves such as Morton or Hilbert ordering. These keys are then used to create the tree data structure while keeping data locality for efficient neighbor computation.
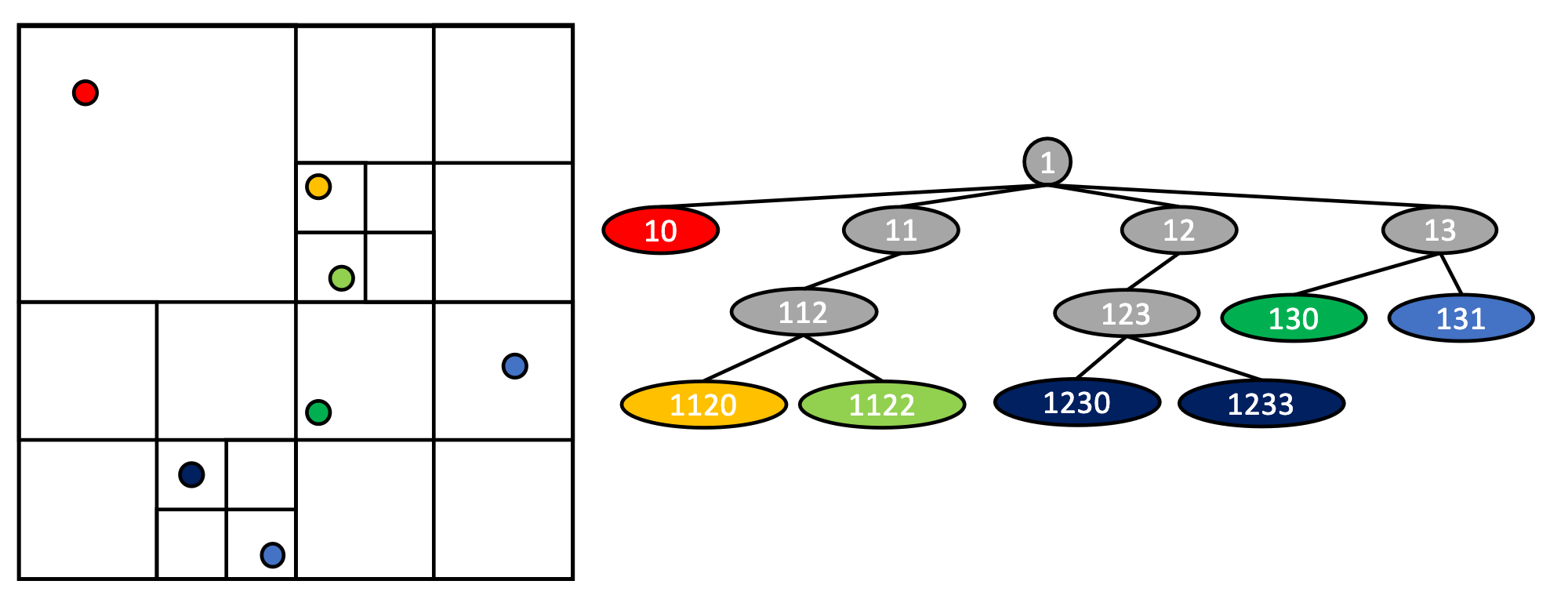
Fig. 10 Two dimensional N-Tree construction based on keys using Morton ordering.
On the left figure we can see that the space is divided in quadrants (for two dimensions). If multiple particles are in the same quadrant, we divide it in four, using the Morton ordering (also called the Z-order). These quadrants are labeled 0, 1, 2, and 3 for the top left, top right, bottom left, and bottom right respectively (forming a “Z” shape in space). Each time a quadrant is divided, these indices are concatenated to form a key. We can find the same decomposition in the N-Tree on the right figure.
The implementation is based on four files:
ntree_sph.hh: The SPH specialization of the N-Tree. It will be used to illustrate the different tree traversals methods.ntree.cc: The Sod shock tube implementation, creates the N-Tree and uses tasks to evolve the simulation.sph_physics.hh: Provides the physics used in the tasks ofntree.cc.control.hh: The different control points to run the example.
In this document we will refer to the leaves of the N-Tree as entities. In this example the entities will represent the particles in SPH. The other components of the tree are called nodes and are a separate index space.
The keys will refer to the space-filling curve values associated with the entities and nodes.
We will first focus on the ntree.cc file which implements the Sod shock tube, using the specialization described later. We will not detail all the tasks and the physics involved, but this will give us an opportunity to explore the capabilities of the N-Tree.
Control Model
This example uses the FleCSI control model with four actions:
initialize_action: Generates the N-Tree topology and populates the different fields with initial data.iterate_action: This cycle in the control model loops over the physics functions to compute the Sod shock tube interactions.output_action: This action outputs information about the simulation to text files, per iteration and per color. It is part of the cycle.finalize_action: This action assembles each iteration information from all colors into one text file per iteration on color 0.
The control model can be represented as:

Fig. 11 The control model for the N-Tree tutorial.
N-Tree Setup and Fields
The N-Tree setup happens in initialize_action:
const int nents = sph::n_entities.value();
s.allocate(cp.sph_ntree,
sph_ntree_t::mpi_coloring(s, s.runtime().processes(), nents),
nents);
auto rho = density(*cp.sph_ntree);
auto p = pressure(*cp.sph_ntree);
auto v = velocity(*cp.sph_ntree);
auto u = energy(*cp.sph_ntree);
auto is_w = is_wall(*cp.sph_ntree);
s.execute<init_sodtube_task>(*cp.sph_ntree, rho, p, v, u, is_w);
sph_ntree_t::build_ntree(s, *cp.sph_ntree);
Firstly, the initial information about the entities is retrieved, either from a file or directly generated in the program. In this example we compute this information directly in the program. This vital information is used to create the N-Tree data structure through our SPH specialization using coordinates, mass, and radius.
The coloring sph_ntree_t::mpi_coloring is constructed internally via the color function from the specialization. It defines how the particles are distributed among all the colors. In this example the specialization just provides a simple load-balancing scheme with an equal number of entities per color.
scheduler::allocate creates a topology instance, filling in the sph_ntree_t::ptr argument and calling sph_ntree_t::initialize to creates the basic memory layout to input the initial particle information.
Before generating the N-Tree data structure, we must populate the different user-defined fields.
These fields are defined at the top of the ntree.cc file:
const field<double>::definition<sph_ntree_t> density, pressure, energy,
d_energy, velocity, acceleration, sound_speed;
const field<bool>::definition<sph_ntree_t> is_wall;
The fields are added to the collection of fields that are already provided on the entities index space by the N-Tree topology and populated in the specialization:
e_keys: entities keyse_colors: entities colorse_i: entities interactionsn_i: nodes interactions
These specific fields, tied to the N-Tree topology and vital for its operation, can be accessed through the topology accessor.
The task init_sodtube_task shows the access to both this topology accessor and the accessors to the different fields added by the user. We are passing all the fields to a function handled by the physics part of the tutorial in the file sph_physics.hh called via sph::init_physics.
// init_sodtube_task
void
init_sodtube_task(sph_ntree_t::accessor<ro, na> t,
field<double>::accessor<wo, na> rho,
field<double>::accessor<wo, na> p,
field<double>::accessor<wo, na> v,
field<double>::accessor<wo, na> u,
field<bool>::accessor<wo, na> is_w) noexcept {
sph::init_physics(t, v.span(), rho.span(), p.span(), u.span(), is_w.span());
} // init_sodtube_task
The entities can then be looped over to initialize their data. This is presented in the next subsection, demonstrating different access patterns.
The last step of the initialize_action is to generate the N-Tree topology using the information provided to the specialization. After this call, the topology is ready to be used: the tree is built and can be used to find neighboring entities.
Entities/Nodes Access
The N-Tree features several ways to access entities/nodes and their neighbors. The different access methods are:
t.entities(): Returns a list of local entities. This function can be templated on the kind of entities to loop over:t.entities<exclusive>: Default behavior, loops over local entities.t.entities<ghost>: Loops over all ghost entities.t.entities<>: Loops over all entities, ghosts and locals.
t.entities(node_index): Returns all the entities (ghosts and locals) under a specific node.t.neighbors(entity_index): Performs a tree traversal, using the iteration methods featured in the specialization, to return a list of the neighboring entities of theentity_indexentity. This list can contain indices of both ghost and local entities.t.nodes(): Returns a list of local nodes. The behavior for the templated version is the same ast.entities<>()but for nodes.t.nodes(node_index): Returns a list of nodes under a specified node index.
These different methods are illustrated in the different tasks/functions present inside the sph_physics.hh file. A good example is the computation of the density:
// Compute density
template<typename T>
void
density(T && t, flecsi::util::span<double> rho) {
forall(e, t.entities(), "density") {
rho[e] = 0;
for(auto n : t.neighbors(e)) {
const double h = (t.e_i[e].radius + t.e_i[n].radius) * 0.5;
const double x =
std::abs(t.e_i[e].coordinates[0] - t.e_i[n].coordinates[0]);
rho[e] += t.e_i[n].mass * kernel(x, h);
}
};
} // density
The user is looping over all the local entities with t.entities() and, for each entity e, loops over all the neighbors of this entity with t.neighbors(e).
Another set of accessors are available for the N-Tree and are used inside the specialization (file ntree_sph.h). We will explore the specialization in the next part, intended for specialization developers.
These other accessors allow the user to perform different kind of tree traversals, used in the compute_centroid function as t.dfs<ttype_t::reverse_preorder, local>().
The N-Tree interface features two kinds of traversals: depth-first search (DFS) and breadth-first search (BFS). The DFS is decomposed into four possible traversals: pre-ordered, post-ordered, reverse pre-ordered, and reverse post-ordered.
The user can then ask to access the entities for each node with the other accessors presented above: t.entities(n_idx) with n_idx the current node.
Specialization
The specialization is presented in the structure sph_ntree_t in the file ntree_sph.hh.
This part is out of the scope of what is needed for a user and is dedicated to specialization developers.
This N-Tree specialization for SPH specifies the mandatory options of the N-tree:
//-------------------- Base policy inputs --------------------- //
static constexpr flecsi::Dimension dimension = 1;
static constexpr flecsi::util::id max_neighbors = 32;
using key_int_t = uint64_t;
using key_t = flecsi::util::morton_key<dimension, key_int_t>;
// In this hashing function we use the low bits (less than 22) to scatter the
// leaves but gather the roots. This is particularly efficient since the roots
// are accessed more often during the neighbor search.
FLECSI_INLINE_TARGET static std::size_t hash(const key_t & k) {
return static_cast<std::size_t>(k.value() & ((1 << 22) - 1));
}
template<auto>
static constexpr std::size_t privilege_count = 2;
The most important point in these options is the key_t structure. This is the space-filling curve that is used to build the N-Tree structure and distribute the entities while keeping them locally close. The space-filling curves values are called keys in this tutorial.
FleCSI provides two different space-filling curves: Morton (Z-Order) and Hilbert ordering.
Interactions
One of the features of the N-Tree is to compute neighboring entities. To compute the interaction list, the user needs to provide the data-structure used for this computation and the associated functions.
To compute the interactions, the user provides the data structure with the minimum information needed for both the nodes and the entities:
struct node_data {
point_t coordinates;
double mass;
double radius;
}; // struct node_data
struct entity_data {
point_t coordinates;
double mass;
double radius;
}; // struct entity_data
The interaction function(s) will compute node-entity, entity-entity, and node-node interactions.
In this example all the interactions are computed the same way, and are represented in the intersect function. This templated function returns true if there is an interaction, i.e. the spheres representing the node(s) or entity(ies) are overlapping.
template<typename T1, typename T2>
FLECSI_INLINE_TARGET static bool intersect(const T1 & in1, const T2 & in2) {
return distance(in1.coordinates, in2.coordinates) <=
in1.radius + in2.radius;
} // intersect
Coloring
The current version of the N-Tree restricts users to only one-color-to-one-process match.
The initial particle distribution is described in the color function of the specialization:
// N-Tree coloring
static coloring color(flecsi::Color size, flecsi::util::id nents) {
const flecsi::util::id hmap_size = 1 << 20;
coloring c(size, hmap_size);
for(auto bin : flecsi::util::equal_map(nents, size))
c.nodes_sizes_.emplace_back(
c.entities_sizes_.emplace_back(bin.size()) + 100);
return c;
} // color
In this simple coloring, we split the total number of entities nents evenly across all colors in c.entities_sizes_. We don’t pre-compute or handle the number of nodes c.nodes_sizes_ carefully in this example, we set them to be 100 more than the number of local entities.
The color function is also used to generate the basic information needed from the entities in a std::vector passed to it. The data can be extracted from a file or, in this case, generated in the physics module sph_physics.hh.
Tree generation and reset
The structure of the N-Tree is created by the initialize function.
It launches init_fields as an MPI task to allow access to data not stored in FleCSI fields (here, just the offsets that are managed by the current process):
static void initialize(flecsi::scheduler & s,
sph_ntree_t::topology & nt,
const coloring & c,
flecsi::util::id nents) {
auto lm = flecsi::data::launch::make(s, nt);
const auto ours = flecsi::util::equal_map(
c.nparts_, s.runtime().processes())[s.runtime().process()];
std::vector<flecsi::util::id> offsets;
auto b = c.entities_sizes_.begin();
auto o = std::accumulate(b, b + ours[0], 0);
for(const auto i : ours) {
offsets.push_back(o);
o += b[i];
}
flecsi::execute<init_fields, flecsi::mpi>(lm, nents, offsets);
}
It uses a launch map to support initializing a topology with a number of colors other than the number of point tasks (which must be equal to the number of processes for an MPI task).
static void init_fields(
flecsi::data::multi<sph_ntree_t::accessor<flecsi::rw, flecsi::na>> t,
const std::size_t nents,
const std::vector<flecsi::util::id> & offsets) {
assert(offsets.size() == t.depth());
flecsi::Color col = 0;
for(auto [c, a] : t.components()) {
std::fill(a.e_colors.span().begin(), a.e_colors.span().end(), c);
sph::init_base(a.e_i.span(), a.e_ids.span(), nents, offsets[col++]);
}
} // init_fields
This function illustrates the use of the multi-color accessor that corresponds to a launch map: components returns the individual accessors, labeled with their colors so that the appropriate initialization can be performed for each.
(Here the multi provides topology accessors, but normal field accessors or mutators can also be used; a task can use multiple multi-color accessors in parallel by indexing into the range returned by components.)
build_ntree constructs the initial tree based on the field values provided by the application.
After an iteration, the entities might have moved to new positions. Thus, their associated keys have changed.
To use the N-Tree efficiently, we reset the N-Tree and re-generate the data structure at each timestep. This is performed in the sph_reset function.
These two functions are using a similar helper method generate_ntree:
// Compute the range of the domain, the keys for each entities and generate
// the N-Tree data structure
static void generate_ntree(flecsi::scheduler & s,
sph_ntree_t::topology & nt) {
// Initialize key values: compute range and keys
{
flecsi::topo::global::topology red(s, 1);
auto r = range_reduction_f(red);
s.execute<init_reduction>(r);
s.execute<range_task>(nt, r);
s.execute<keys_task>(nt, r);
}
nt.make_tree(s);
s.execute<compute_centroid<true>>(nt);
s.execute<compute_centroid<false>>(nt);
nt.share_ghosts(s);
} // generate_ntree
The generate_ntree function is called in both build_ntree and sph_reset after initializing the fields or resetting the N-Tree data structure, respectively.
This helper computes the range of the domain and the keys for each entity, then the N-Tree topology is ready to be generated.
In the first step ts->make_tree(s):
The entities are sorted globally based on the value of their keys. This sort ensures the locality of the entities on each color.
The local tree is then created, and the top of all local N-Trees is shared with all colors. This allows each color to have overall information about the N-Tree and to know which color owns which subtree.
To compute ghost information for all entities, the user needs to provide the interaction information. In this example, we are computing the center of mass for each node in the N-Tree. We are then using these centers of mass as the center of the sphere for the interaction function described earlier.
In the last step, we compute and share the ghost entities. This creates the data structure needed when ghost_copy is triggered by a task.
After these steps, the N-Tree data structure is ready to be used, the neighboring information will be available for each entity.
Solver
The simulation repeatedly invokes actions to advance the simulation state and write output from it. The former launches several related tasks:
void
iterate_action(sph::control_policy & cp) {
auto & s = cp.scheduler();
auto rho = density(*cp.sph_ntree);
auto p = pressure(*cp.sph_ntree);
auto u = energy(*cp.sph_ntree);
auto v = velocity(*cp.sph_ntree);
auto dvdt = acceleration(*cp.sph_ntree);
auto dudt = d_energy(*cp.sph_ntree);
auto is_w = is_wall(*cp.sph_ntree);
flog(info) << "Iteration: " << cp.step << '\n';
s.execute<density_task>(*cp.sph_ntree, rho);
s.execute<eos_task>(*cp.sph_ntree, p, rho, u);
s.execute<acceleration_task>(*cp.sph_ntree, dvdt, v, rho, p, u);
s.execute<dudt_task>(*cp.sph_ntree, dudt, v, rho, p, u, is_w);
s.execute<advance_task>(*cp.sph_ntree, v, dvdt, u, dudt, is_w);
sph_ntree_t::sph_reset(s, *cp.sph_ntree);
}
The permissions of the accessors used by these tasks determine the communication structure of the iteration:
density_task(sph_ntree_t::accessor<ro, ro> t,
field<double>::accessor<wo, na> rho) noexcept {
eos_task(sph_ntree_t::accessor<ro, na> t,
field<double>::accessor<wo, na> p,
field<double>::accessor<ro, na> rho,
field<double>::accessor<ro, na> u) noexcept {
eos_task can run as soon as density_task completes, without an intervening ghost copy for rho, because it does not read the ghost elements.
acceleration_task(sph_ntree_t::accessor<ro, ro> t,
field<double>::accessor<wo, na> dvdt,
field<double>::accessor<ro, ro> v,
field<double>::accessor<ro, ro> rho,
field<double>::accessor<ro, ro> p,
field<double>::accessor<ro, ro> u) noexcept {
That ghost copy, as well as the one for p, must however take place before acceleration_task can execute, since it reads the ghosts for both.
dudt_task(sph_ntree_t::accessor<ro, ro> t,
field<double>::accessor<wo, na> dudt,
field<double>::accessor<ro, ro> v,
field<double>::accessor<ro, ro> rho,
field<double>::accessor<ro, ro> p,
field<double>::accessor<ro, ro> u,
field<bool>::accessor<rw, ro> is_w) noexcept {
dudt_task reads the ghosts for rho and p again, but no second copy is needed since no writes have taken place since the first.
advance_task(sph_ntree_t::accessor<rw, na> t,
field<double>::accessor<rw, na> v,
field<double>::accessor<ro, na> dvdt,
field<double>::accessor<rw, na> u,
field<double>::accessor<ro, na> dudt,
field<bool>::accessor<ro, na> is_w) noexcept {
The write to the topology structure data t necessitates a ghost copy before the next density_task, but the output reads only owned data and can proceed immediately.